
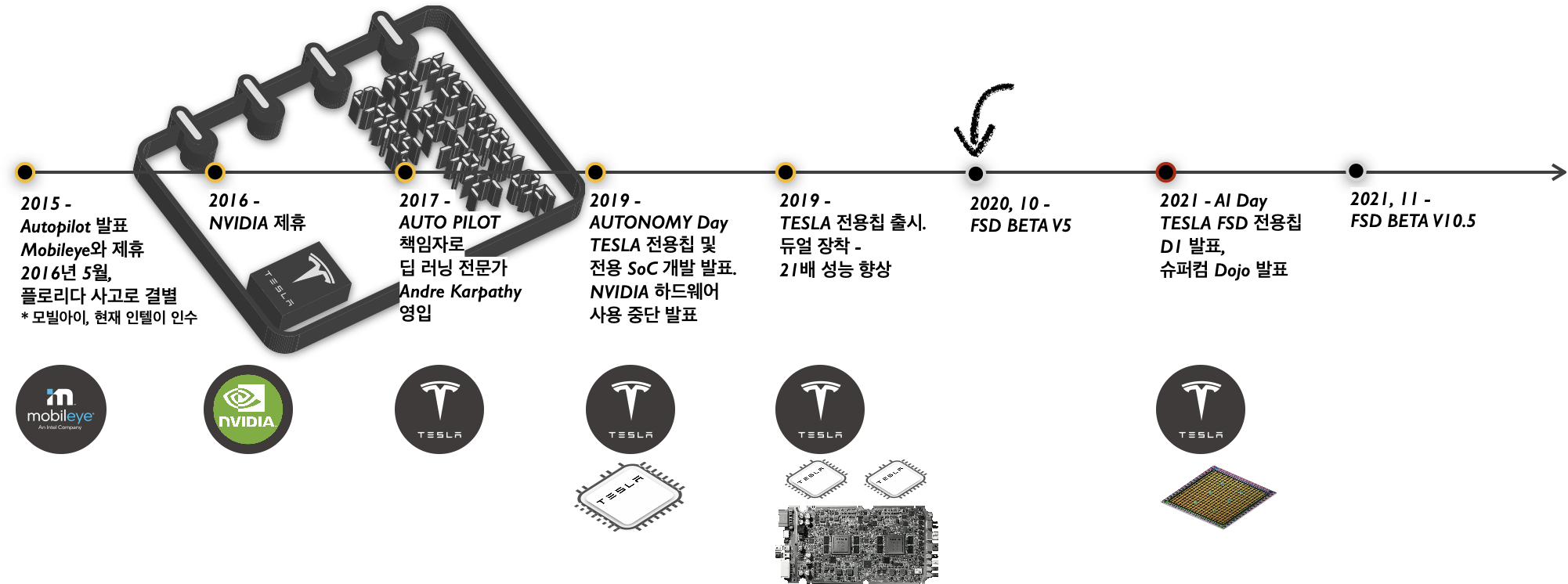
테슬라 (TESLA) - 자율주행과 AI

몇 년 전부터 '일론 머스크(Elon Musk)'는 Lv5에 이르는 테슬라의 '완전 자율주행(Full Self Driving, 이하 FSD)'이 다음 해에 이루어질 것이라고 해마다 이야기해왔다. 2021년 8월 19일, 발표된 ’AI 데이'는 테슬라 FSD의 퍼블릭 베타 버전 5가 테슬라 차량 소유자에게 배포된 지, 약 10개월(2020년 10월)이 지난 후였다. AI Day가 발표된 당일은 FSD 새로운 베타 버전 9가 업데이트된다고 하였다. 현재는 버전 10.5이다. 참고로 베타 버전은 약 2,000명의 테슬라 차량 소유자가 참가하여 미국에서만 테스트 중이다.
전기차 역사에 첫 페이지를 쓰고 있는 '일론 머스크'와 테슬라. 애석하게도 AI 데이 이후, 새로운 FSD BETA 버전의 크고 작은 오류들이 사고로 이어졌고, 이로 인해 <자율주행>이라는 단어 사용을 제한해야 한다는 사회적인 반작용도 적지 않게 생겨나고 있다. 현재도 테슬라는 오류들을 수정하여 '베타 N 버전'의 업데이트를 지속하고 있다.
그런데 국내, 테슬라를 소유하고 있는 주변인들은 테슬라의 기존 '오토파일럿'은 '상당히 괜찮다'로 일관된 평가를 하고 있다. 물론 비교 대상이 딱히 없다는 것이 비극이라면 비극이다. 테슬라도 테슬라지만, AI 발전 속도에 더 놀라는 사람도 적지 않았을 것 같다는 생각이다.
| 사회적 분위기 - 자율주행, 아직도 갈 길이 멀다. 라이다 없이 위험하다. |
"라이다(Lidar)는 필요 없지만 성능, 효율 모두 뛰어난 전용 칩(Chip)은 필요해!"
AI가 언제부터 이렇게 발전한 거지? 성능이 좋으면 효율이 떨어지고, 효율이 좋으면 성능이 떨어지는 반도체의 양자 간의 관계는 나아가 소프트웨어와 하드웨어의 불균형으로 이어지곤 하였다. 그랬던 반도체가 성능과 효율이 동시에 개선되기 시작했다. 심지어 개발된 소프트웨어에 맞춰 하드웨어를 별도 제작하는 업체들까지 생겨나고 있다.
딥러닝의 대세, 거의 모든 개발을 딥러닝으로 선회하는 최근 트렌드도 하드웨어의 개선이 가장 큰 원인일 것이다. 이런 식으로라면 AI는 거의 모든 곳에 적용될 가능성이 매우 커졌다는 생각이다. 나아가 AI의 대중화 시대가 곧 올지도 모르겠다. 하드웨어만 받쳐주면 곳곳에서 사용될 곳이 너무 많기 때문이다.
테슬라의 자율주행은 컴퓨터 시각 기술을 지칭하는 '컴퓨터 비전'과 딥러닝 방식의 인공신경망인 '뉴럴 넷'으로 구축되고 있다. AI Day를 통해 곧 무언가 이루기는 하겠구나라는 생각이 솔직히 너무 많이 들었다. 이 모든 기술 스택을 완벽히 구현할 D1과 슈퍼컴퓨터까지 등장하는 부분에서는 테슬라의 잠재력과 미래가치는 둘째치고 여러 생각에 마음까지 복잡해지더라는.
왜냐면 어차피 AI는 알고리즘과 최적화된 데이터를 학습하는 것으로, 시간과 다량의 데이터가 정량적으로 필요한 분야이다. 만약 누군가가 제대로 된 알고리즘과 제대로 된 데이터를 가지고 차근차근 AI를 트레이닝하여 구축하고 있다면 가장 먼저 시작한 사람이 가장 잘하게 될 가능성이 높게 된다. 양자 컴퓨터와 같이 말도 안 되는 컴퓨터가 나오지 않는다면 말이다. 테슬라는 업계 최고의 인재만 영입하여 AI에 필요한 모든 펀더멘틀을 구축하는 것으로 잘 알려져 있다.
* 테슬라는 최고 스펙으로 2017년(Andrej Kaparthy 영입)부터 컴퓨터 비전 기술과 딥러닝으로 AI 자율주행을 구축하고 있다.
"어려워도 너무 ¹⁰⁰ 어려운 자율주행 - 근래 회자되는 모든 핫 테크의 접목 "
자율주행, 생각해보면 엄청난 '인류 문명의 사건'으로 기록될만한 하이테크 집약 끝판왕이다. 이를 전제로 레이더, 라이다와 같은 하드웨어 또한 상대적으로 기술과 효율을 높이고 있는 것도 사실이지만 소프트웨어의 경우, OS는 물론이요, 도로 위의 모든 시나리오를 예측하고 실행해야 하는 AI까지 필요하며, 성능 좋은 반도체와 지구 곳곳에서 운행되고 있는 차량 제어를 위해 슈퍼컴퓨터는 필수가 되었다. 다시 말해 금세기 회자되는 모든 '핫 테크'들을 모두 갖추고 융합해야 하는 상황이다. 최근 미디어의 사설을 접하자면 하드웨어와 AI 때문에 'OS'가 뒤로 밀린 느낌마저 든다. 그렇다. 하나같이 만만치 않은 일이다. 마이크로소프트까지 망각하게 한, OS 때문에 애플이고, OS 때문에 구글이었다는 것을 잊어서는 안 된다.
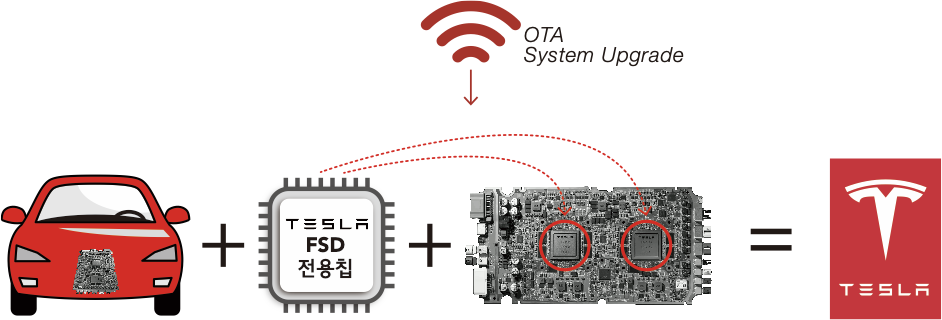
현재 각 자동차 업계들이 독자개발을 추구하는 자율주행도 자율주행이지만, 얼마든지 아웃소싱으로 해결되던 애플리케이션이 아닌, 자율주행을 위한 시스템을 OTA 방식으로 빠르게 업데이트하는 소프트웨어의 셋업부터 하나같이 쉽지 않을 것 같다는 생각이다. 게다가 엄청난 개발 비용이 마련되지 않으면 불가능한.

아이폰, 안드로이드와 같은 방식의 업그레이드 방법으로써, Over The Air의 약자이다. 테슬라는 모든 신차에 ‘오토파일럿(Auto pilot)’ 기능과 향후 이용 가능한 FSD에 대응한 첨단 컴퓨터 하드웨어를 표준 장비하고 있으며, 무선통신을 이용하여 OS와 펌웨어와 같은 소프트웨어를 매번 갱신하는 OTA 기술에 의해 FSD를 업그레이드하는 방법을 채용하고 있다.
◈ 기술 전쟁으로 생겨난 전례 없는 스와핑 - 그리고 미래의 직업을 심각히 고민해야 할 때.
아이폰 이후, 이른바 '고인 물이 썩는다'는 교훈으로 '시대정신'에 지나치게 매몰된 실리콘 벨리의 인재 영입 전쟁은 누가 누구의 남편이고, 누구의 와이프인지 헷갈릴 정도로 하루가 멀다 하고 경쟁사 인재 스와핑이 일어나고 있다. 한쪽에서는 실업자가 늘어나고 있는데, 한쪽에서는 사람이 없어 전쟁을 벌이고 있는 것이다. 만약 이 글을 읽는 사람 중에 어린 자식이 있는 사람은 장래에 우리 아이가 어떤 직업을 가져야 하는지, 한 번쯤 고민을 했으면 좋겠다는 생각이다.

TESLA, 그들의 자율주행 완성을 위한 방법 - 뉴럴 넷 "AI"
'라이다(Lidar)'를 사용하지 않겠다는 일론 머스크는 라이다는 물론이요, 심지어 기존의 '레이더(Radar)'까지 2021년 5월부터 일부 모델을 시작으로 탑재하지 않겠다고 하였다. 그런데 유독 시스템 반도체 개발에는 온 힘을 쏟아붓고 있다. 엄밀히 이야기하면 GPU이다.(라고 썼지만 D1은 NPU라고 하네요. 쏘리~)

GPU는 (Graphics Processing Unit)의 약자로, 직역하면 ‘그래픽 처리 장치’이다. 시스템 반도체 중 하나이며, CPU에 비하여 성능은 떨어지지만 비교적 복잡하지 않은 연산의 경우, 빠르게 처리하는 장점을 가진다. 컴퓨터 비전 체계에서 필요한 데이터를 수집하는 경우, 대부분 2차원의 원시 이미지를 처리하게 되므로 CPU와 같은 고성능 반도체보다는 GPU로 처리하는 것이 여러모로 효율이 높게 된다. 또한 다이 크기도 상대적으로 작기 때문에 전력 소모율도 적을 뿐 아니라 병렬식으로 연결하게 되면 쉬운 데이터 처리를 엄청나게 빠르게 진행할 수 있게 되므로 부피를 더욱 마이크로 화하여 개수를 늘려 성능을 배가시키는 방식으로 진화되고 있다. 비트코인과 같은 블록체인을 채굴하기 위해 많은 연산 처리가 필요한 경우도 예외는 아니며, 실제 많은 비트코인 채굴자들로 인해 수요가 많아져 GPU 가격은 해마다 상승하였다. GPU는 진화를 통해 빅 데이터 처리와 AI에 최적화되어 있는 반도체로 자리매김하고 있다.
과연 AI 강화만으로 가능할까?
테슬라는 AI 강화만으로 자율주행이 완성될 것이라는 확고한 믿음을 가지고 있는 것 같다. 현재 테슬라는 자율주행으로 '인공신경망'이라 불리는 딥러닝 기반의 '뉴럴 넷(Neuralnet)'과 '컴퓨터 비전' 기술로 모델의 밑그림을 그리고 있다. (AI계에서 밑그림이란, 엄청난 모델과 데이터 구축에 가장 중요한 부분이다. 모델에 최적화된 양질의 데이터여야 한다는 전제까지 포함된다. 데이터가 모델 완성 작업의 거의 80%를 차지하기 때문이다.)
일론 머스크와 'Open AI' 시절부터 인연을 이어온 테슬라의 '컴퓨터 비전' 책임자 '안드레 카파시 (Andrej Karpathy)'는 테슬라의 '오토노미 데이(Autonomy Day)'에서 일론 머스크를 통해 "최고의 AI 개발자"로 소개된 바 있다. 실제 그는 딥 러닝 계의 우수한 바이오 그래피를 가지고 있는 유능한 인재이며 특히 AI계의 컴퓨터 비전 분야에서 현재 가장 주목받고 있는 인물이 되었다.
| 안드레 카파시 (Andrej Kaparthy) - Biography |
2017~ - Tesla AI 수석 이사
2016~2017 - OpenAI의 연구원(딥 러닝, 생성 모델, 강화 학습)
2011~2015 - Stanford 컴퓨터 과학 박사 학위 (딥 러닝, 컴퓨터 비전, 자연어 처리. 고문:Fei Fei Li.)
2009~2011 - 브리티시 컬럼비아 대학교(물리적 시뮬레이션 수치를 위한 MSc 학습 컨트롤러. 고문: Michiel van de Panne)
2005~2009 - 토론토 대학교: 컴퓨터 공학 및 물리학 - 복수 전공

연방 정부, 미국 전역 판매된 테슬라 자동차, 오토파일럿 관련 안정성 조사 착수

NHTSA는 이전에도 Tesla 차량의 오토파일럿 기능 관련, 안정성에 대하여 조사한 바 있었다. 이전 조사 발표에 의하면 대부분의 오토파일럿과 관련된 사건이 어두워진 후에 비상 차량 조명 및 기타 조명이 깜박이는 곳에서 발생했다는 보고가 포함되어 있었다. 라이다 사용을 기피하는 부분에 대한 권고 조치로 라이다의 필요성을 강화할 수 있는 상황이라고 '헤이더 라다(Hayder Radha)’ Michigan State University 전기 및 컴퓨터 공학 교수는 말하고 있다.
그러나 테슬라는 운전자 부주의 경고 서비스와 사용자에게 차량 인도와 함께 직간접적으로 운전자 참여의 절대적 중요성을 알리고 있다. 대외적으로 일론 머스크의 ‘완전 자율 주행’의 실행 임박 메시지 등이 테슬라 사용자들의 경각심을 상쇄시키는 원인이라고 말한다면 어쩔 수 없지만.

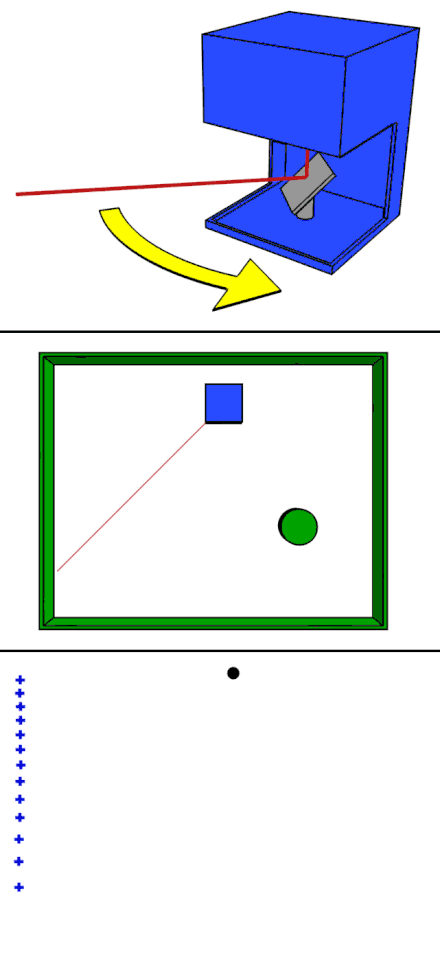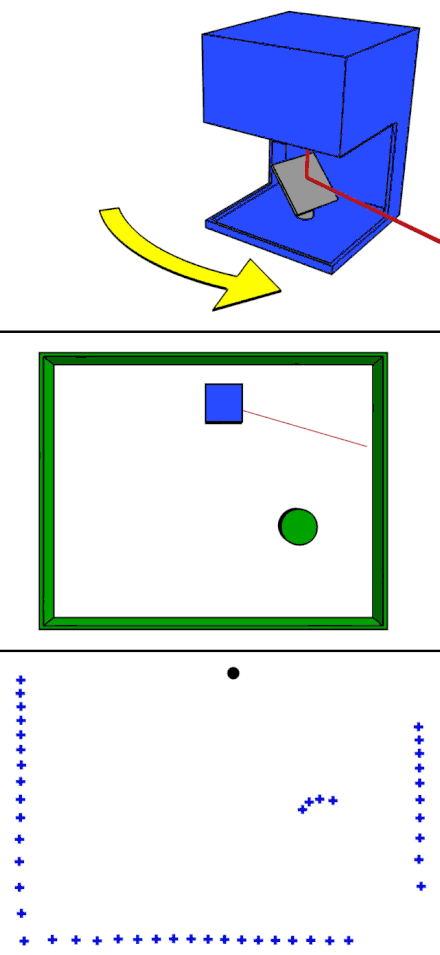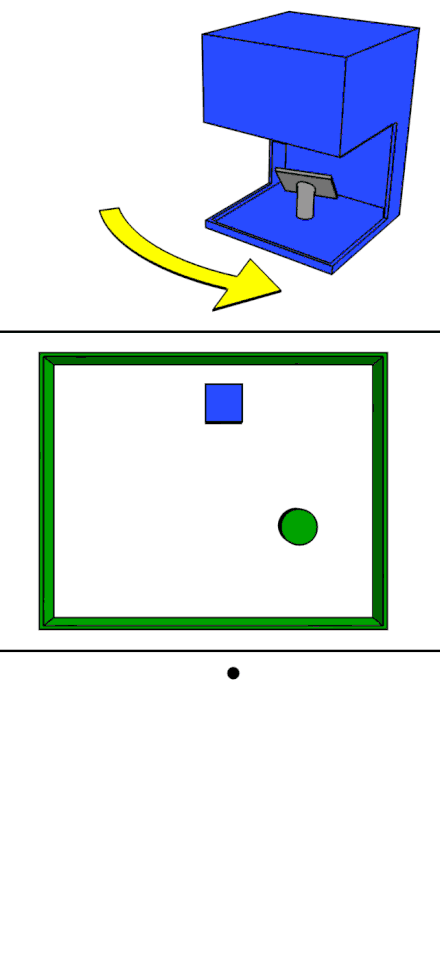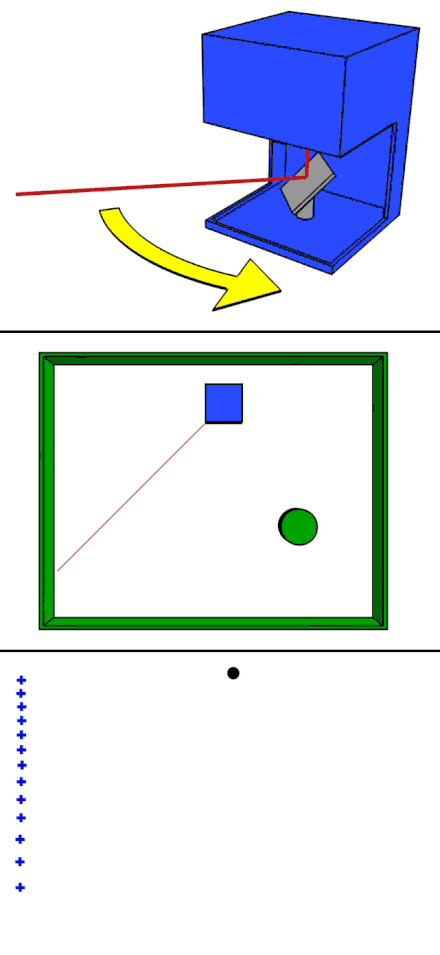
라이다(LIDAR/LiDAR, light detection and ranging" 또는 "laser imaging, detection, and ranging"의 약자))는 레이저 펄스를 쏘고 반사되어 돌아오는 시간을 측정하여 반사체의 위치 좌표를 측정하는 레이더 시스템이다. (위키백과)
라이다도 레이더의 한 종류이다. 라이다는 대부분, 근적외선 레이저빔을 펄스 상태에서 대상물에 쏜 후, 빛이 닿아 튀어 되돌아오기까지의 시간차를 측정하는 방식이다. 간단하게 레이저 스캐너라고 생각하면 좋을 것 같다. 좋은 점은 대상물의 거리뿐만 아니라, 위치나 형태까지도 측정이 가능하다는 것이다. 저녁이나 빛이 없는 공간에서도 물체 측정이 가능한 장점이 있는가 반면, 악천후에는 사용하기 어려워 단점이 되고 있다. 그래서 자율주행의 경우, 악천후에 대비된 밀리파 레이더를 함께 사용한다. 라이다 기술은 현재 자동차 업계에서 자율주행 레벨 5 실현에 필수 불가결한 기술이라 여기는 것이 일반적이다. 때문에 라이다 시장은 해마다 급성장하고 있다. 자율주행에 필요한 하드웨어로 카메라, 밀리파 레이더(Radar), 라이다(Lidar)를 꼽는다. 괜찮은 라이다 제조사들도 상당히 많다. 불행히도 가격은 비싸다. 최근에는 작고, 저렴한 라이다도 개발되고 있다.
웨이모, 크루즈, 볼보, 메르세데스, 포드, GM 모두 라이다를 사용하건만. 도대체 왜 테슬라는 AI만 고집할까?

AI Day가 열리기 약 2달 전, 컴퓨터 비전 학술대회, CVPR에서 테슬라 Computer Vision 책임자, ‘안드레 카파시’가 워크숍을 통해, 라이다 제외와 자율주행에 대한 테슬라의 입장을 이야기하였다.
❶ 라이다를 제외시킨 이유
라이다(Lidar)는 레이저를 다중으로 빠르게 쏘고 난 후, 360도의 전체 지형, 지물을 읽은 후에 사전 맵핑(Mapping)하고, 다시 ‘고화질 지도(HD Map)’로 옮기는 방식으로서, 결국 장치 설치에서부터 장치의 정보 수집, 구현 및 유지 관리하는 과정 자체가 볼륨이 커서 확장이 불가하고 인프라를 최신 상태로 유지하는 비용이 너무 큼.
* 최근 들어 라이다의 기술도 효율적으로 진화하여, 보다 가볍고, 콤팩트한 크기, 레이저가 아닌 고속 연사 등으로 공간을 재현하는 대체 방법 등으로 발전을 거듭하고 있으며, 가격도 매우 저렴해지고는 있다. 하지만 용량은 적지 않을 것 같고, 에너지 효율 등의 여부는 알지 못하고 있다.
❷ 레이더까지 제외시킨 이유
레이더의 부정 인식으로 생기는 오류와 노이즈로 인해 AI까지 판단을 잘못하는 사례들의 검토 결과, 레이더가 있을 때, 더 오차율이 높다는 것이 검증되었고, 컴퓨터 비전 인식이 레이더보다 100배 더 정확하게 인식하고 있다고 함. 실제 레이더를 포함하였을 때, 500만 마일당 사고가 발생되었지만, 카메라 비전만 사용한 경우 1500만 마일 주행에도 사고가 발생하지 않음. 뒤이어 이 모든 것의 핵심은 데이터라고 이야기함. - (이 이야기는 아마도 AI 능력이 향상되었다는 것으로 갈음해도 좋을 것 같다. 비전 인식이 레이더보다 낫다는 이야기는 최근에 나온 이야기이다.)
❸ 컴퓨터 비전 기술과 뉴럴 넷만으로도 가능
컴퓨터 비전과 뉴럴 넷만으로 FSD를 완성하는 것은 결코 쉽지 않은 일이라고 함. 사람이 시각만을 이용하여 주변 물체와 깊이와 속도를 이해하면서 운전하는 것처럼 뉴럴 넷도 비슷하게 동작할 수 있는 것은 물론 심지어 사람보다 더 우수하게 할 수 있다는 점을 강조하였고, 무엇보다 테슬라의 뉴럴 넷이 그렇게 완성될 수 있는 가장 큰 이유는 그들이 '함대(Fleet)'라 부르는 전 세계 테슬라 사용자들의 빅 데이터가 있기 때문.
* 실제로 테슬라는 스스로를 '모함(Mother Ship)'이라 칭하고, 전 세계 테슬라 이용자를 '함대(Fleet)'라고 표현하고 있음.
❹ 독보적인 플릿(Fleet) 데이터 - AI 학습 조건 최적화
전 세계 100만 대에 이르는 플릿(fleet)이 있으며, 그들은 단순한 자동차가 아니라 통신망을 통해 실시간 액세스 할 수 있는 컴퓨터라는 것. 테슬라가 사용자들로부터 다량의 데이터를 얻을 수 있는 환경이 독보적으로 마련되어 있는 것은 AI 모델 완성의 적합성을 가지기에 매우 유리한 조건이라는 것. 컴퓨터 비전이 완벽하게 작동하려면 모든 표현 속의 모든 개체를 올바르게 정의할 수 있는 수천에서 수백만 개에 이르는 정량적 데이터가 필요한데, 현재 테슬라는 Fleet 각 차량의 8대의 카메라가 수집한 수십억의 실제 주행 데이터를 보유하고 있다고 함.
❺ 레이블링 자동화
모든 데이터는 비용절감을 위해 Data Auto Labeling 한다고 했는데, 원래 딥러닝은 레이블링이 자동화인 것으로 아는데. 패스~(Karpathy는 특히 실제 도로에서 일어나고 있는 일반적이지 않은 데이터, 즉 돌발 상황 등과 같은 실제 레이블링 자료 획득을 중요하다 이야기한다.)
❻ 쉐도우 모드와 플릿러닝
테슬라 자동차에서 자율주행을 운행하는 뉴럴 넷과 다른 별도의 고성능 뉴럴 넷을 배포하고 가동하여 사전에 레이블링 된 데이터를 이용한 부분적 기능들을 우선 테스트한다. (이것은 실제 작동하고 있는지조차 차량 소유자는 느끼지 못하는 기능이며 특정 레이블링 된 모델의 기능을 실제 차량에 적용시키기 이전에 가상적으로 그 기능을 테스트하기 위한 숨겨진 모드라고 생각하면 좋을 것 같다.) 이것을 ‘쉐도우 모드(Shadow Mode)’라고 한다. 이러한 쉐도우 모드를 통하여 실제 적용할 수 있는지 여부를 테스트하고, 만약 오류가 있다면 작업자가 별도로 레이블링 정리와 검수를 하여 보완하는 작업을 거쳐 쉐도우 모드에서 또다시 학습을 반복시키고 있다. 이것을 ‘플릿 러닝(Fleet Learning)’이라 한다. 이에 완벽한 레이블링으로 확인되었을 때, 실제 차량에 자율주행 요소로 대입시킨다.
❼ 데이터 수집 전략 - 트리거(Triggers)
모든 데이터를 수집하고자 하면 지나치게 데이터가 방대해지며 불필요한 데이터까지 수집될 수 있으므로 사전에 221개의 정의를 마련하여 (트리거라 부름) 정의된 221개의 촉발 사항에 만족한 경우에만 Auto Data Labeling으로 데이터를 수집함. 또한 실제 도로 상황에서 일어나는 다양한 데이터를 얻는 것이 매우 중요하다고 이야기함. 또한 쉐도우 모드를 통해 만약 오류가 있는 부분은 사전 정의된 이 트리거를 이용하여 오류를 찾아내고 있다고 한다. 트리거만 별도로 4개월 동안 개발하였다는.


테슬라가 비전만으로 자율주행을 완성하려는 이유 - 전 세계 서비스 제공 |
전 세계 곳곳에 서비스를 제공하기 위해서이다. 전 세계를 상대로 HD Map을 만들고, 보수하는 것은 굉장히 많은 비용이 발생하기 때문에 현실성이 없다. 만약 비전으로 이 문제를 해결하면 어느 지역에서나 일반화할 수 있기 때문.

그렇다면 컴퓨터 비전 기술과 딥러닝만으로 자율주행을 과연 완성할 수 있을까?

| 시각은 알고보면 지각이다. |
사람은 어떻게 인식하고 시야를 확보하며 운전을 하고 있는 것일까? 우리는 라이다와 같은 입체적 공간과 입체적 사물 인식 기능을 가지고 있기 때문에 운전을 잘하는 것일까? 아니면 레이더와 같은 감각 기질이 뛰어나기 때문일까?
공교롭게도 사람의 눈은 3차원을 보지 못한다. 사람의 눈 또한 2차원의 '선(Line)'만 인식하는 이른바 원시 데이터만 볼 수 있다. 우리가 눈으로 본 공간과 사물을 3차원적으로 인식하는 것은 지각을 통해 사물과 공간을 이해하는 것이며, 보자마자 입체적 사물과 공간을 헤아리는 것은 눈으로 본 사물의 정보를 뇌에서 정보화하여, 3차원으로(입체적으로) 이해하는 과정이 빠르게 일어났기 때문이다.
눈은 원래 '뇌'였다는 이야기가 있다. 발생학적으로 뇌신경의 일부로 발생하였고, 해부학적으로는 뇌신경으로 작용한다. 눈과 뇌는 직접적으로 연결되어 중추신경에 속하며 후두엽에서 관장한다. 후두엽은 시각중추를 관장하는 곳으로 뒤통수에 위치하고 있다. 1차 정보인 시각정보는 후두엽에 의해 위치 및 크기 및 공간까지 아우르는, 인간 생활에 필요한 중요한 정보로 변환된다. 후두엽은 뇌 기능에서 상태와 구조를 이해하는, 매우 고급 정보를 다루는 곳이라 할 수 있다. 손상되면 시신경세포에 전혀 이상이 없어도 시각 정보가 들어오지 않으므로 앞을 볼 수 없게 되기도 한다.

최초 안쪽에서부터 만들어진 인간의 뇌는 원시적(그래도 복잡하지만)이라 할 수 있는 본능적 기능과 호흡과 같은 자율 신경들을 시작으로 오감이라 불리는 여러 감각의 기능들이 그 사이사이 복잡하게 얽혀 있으며 이들을 통해 새로운 정보를 습득할 수 있도록 장치되어 있다. 나아가 뇌 속에 들어온 갖가지 정보들을 각각 부호 처리하고 기억 기능을 통해 저장해 두었다가 기억된 정보 하나, 하나를 별 개화하지 않고, 또 다른 새로운 논리 구성의 재료로 사용하는 연합적 처리를 함으로써 뇌는 궁극적 지각을 발현한다.
눈은 뇌와 밀접하게 빠른 정보를 주고받는 신체기관이다. '시각' 자체가 '지각'이라는 말은 결코 지나치지 않다. 우리가 알고 있는 3차원의 입체적 정보를 스스로 지각함으로써 사물을 이해하는 것이 시각이기 때문이다. 그렇다면 우리가 헤아리는 입체적 구조, 즉 사물과 공간은 스스로 인식하고 있는 정보로 이해되고 있다는 것이다.
| 아는만큼 보인다. 눈 뜬 장님이다. - 새삼 이런 말들이 놀라워지는 |
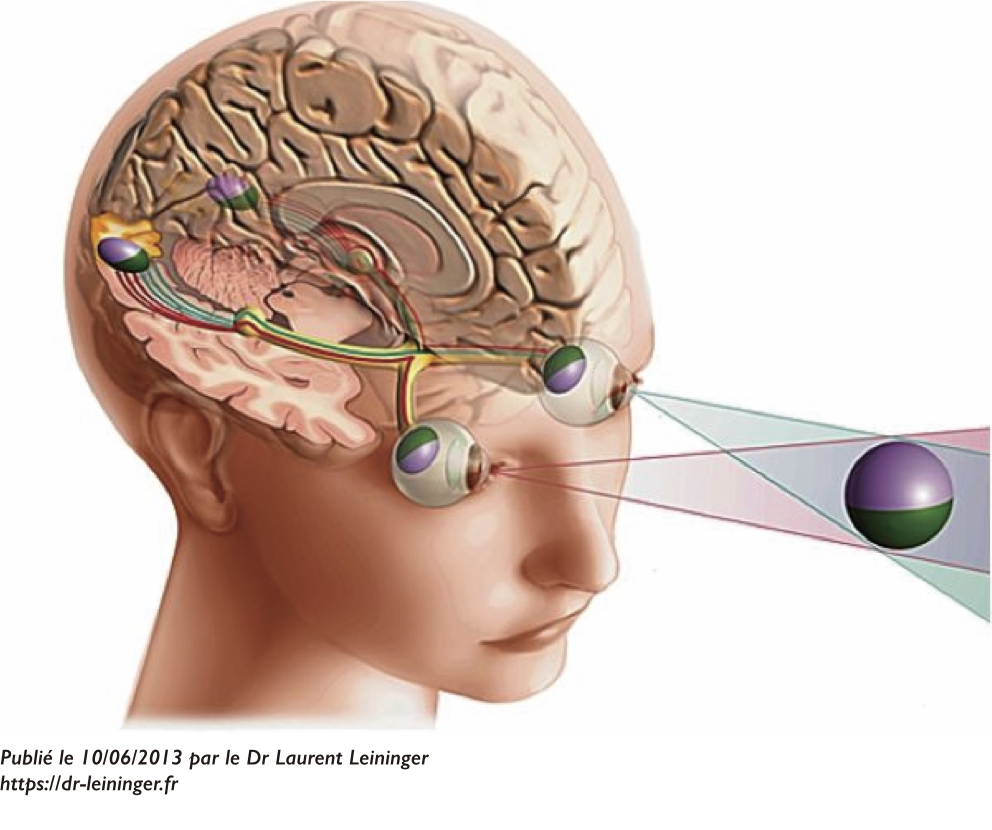
제일 먼저 사물을 눈으로 인식할 수 있는 것은 '빛' 때문이다. 빛이 물체에 반사되거나 혹은 물체 자체가 빛을 방출할 때, 비로소 '시각화'된다. 빛이 제일 먼저 눈의 각막과 수정체와 초자체를 지나 망막의 시세포를 자극하게 되면 대뇌에 신호를 전달한다. 이때 신호를 전달하는 매개체는 '전기(Electricity)'이다.
물체의 높이와 넓이 등, 거리와 깊이, 그리고 위치를 인지하는 이른바 '입체적 시야(Stereoscopic Vision)'의 기능은 6~7cm 정도 떨어져 위치하고 있는 두 눈이 각각 각도와 위치가 다른 영상 정보를 뇌에서 통합하여 입체적으로 해석하는 것이다. 실제로 눈앞의 물체를 한쪽 눈만 뜨고 보면 양쪽 눈에 보이는 물체의 각도가 서로 어긋나는 것을 누구나 확인할 수 있다. 뇌는 이러한 좌우의 어긋남을 이용하여 2차원의 평면적 물체의 깊이를 해석한다. 눈을 통해 수집된 모든 정보는 대뇌의 시각피질에 의해 3차원적으로 통합 해석되어 시각은 비로소 하나의 대상물을 입체적으로 인지하게 되는 것이다. 컴퓨터 비전과 인간의 시각은 둘 다 2차원의 원시 정보를 받아들이고 있으므로 다르지 않은 정보를 취급하고 있다고 할 수 있다. 실제 정보를 받아들이는 인간의 ‘뉴런'이 Karpathy가 만들어 가는 컴퓨터 뉴럴 넷의 ‘노드’에 해당한다. 사람의 기억도 실제로 코딩화되어 존재한다.
| 뉴런 (Neuron) = 노드 (Node) |
안드레 카파시가 보여준 그들의 뉴럴 넷 알고리즘

위의 그림은 AI Day에서 비전 책임자 ‘안드레 카파시’가 테슬라의 ‘뉴럴 넷’을 실제 생물학적 시각 신경계와 똑같이 구축하였다고 설명하였던 그림이다. 다소 상기된 그가 했던 말 중에 가장 기억에 남는 것은 '우리가 인공 생명체를 만드는 것과 같다'라는 표현이었다. 인공신경망(뉴럴 넷)은 사람의 신경망을 모방하여 만든 알고리즘을 뜻한다.

그들의 ‘뉴럴 넷(인공신경망)’은 딥러닝 체계이다. 딥러닝은 여러 층(Layers)으로 구성된 신경망 모델로 천천히 각 층의 표현을 학습하여 의미를 찾는 방식으로 말 그대로 깊이 있는 학습을 해나가는 모델(알고리즘)이다. 이전의 머신러닝은(‘딥(Deep)’과 상반된) ‘얕은’ 학습법으로써 사람이 초기 입력 데이터를 여러 방식으로 변화해서 훈련하였지만 딥러닝은 이러한 단계를 완전히 자동화하고 있다. 레이블링 자동화가 바로 그것이다. (엄밀히 이야기하면 레이블링 자동화 자체도 알고리즘이지만.)
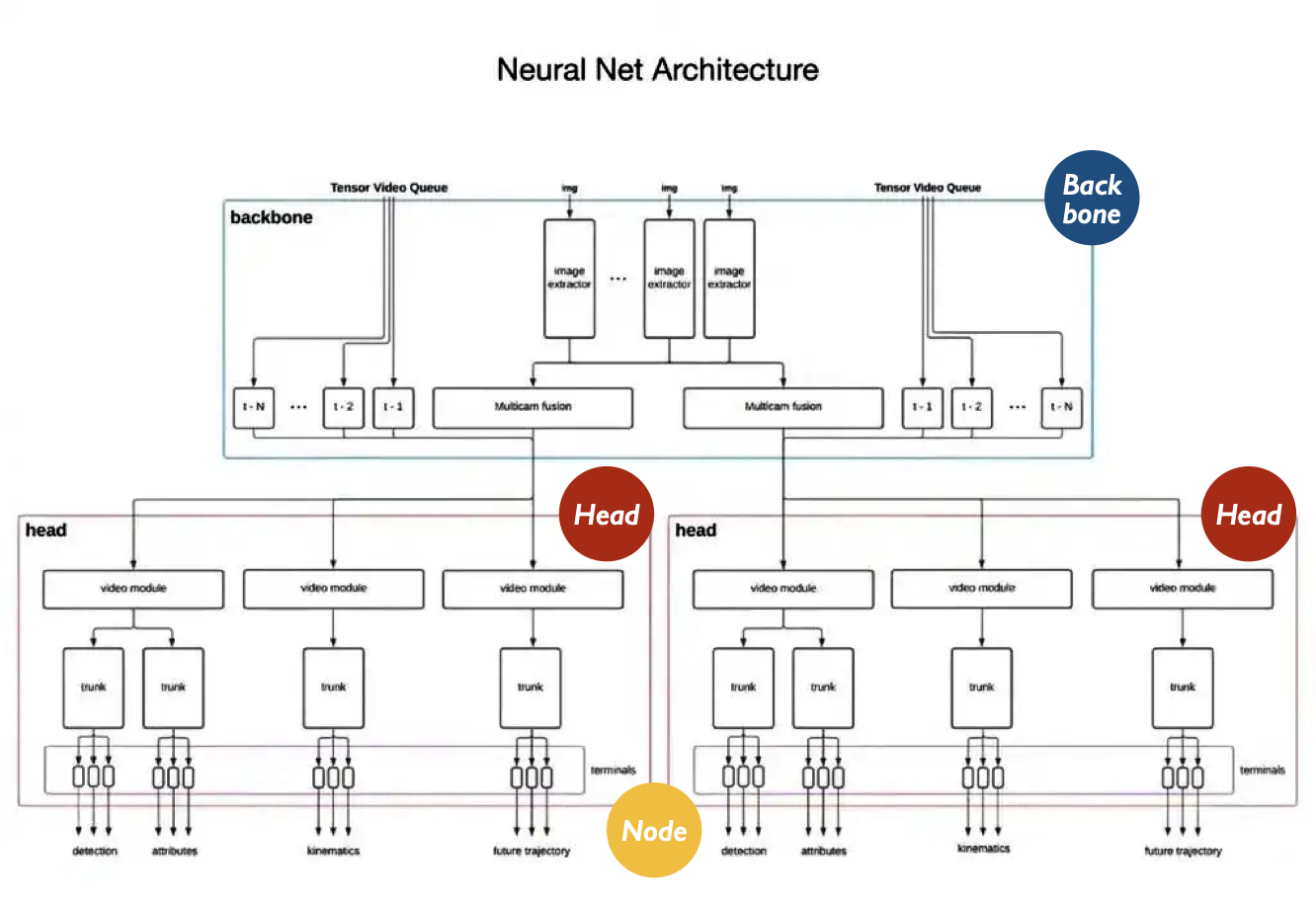
위의 그림은 CVPR에서 소개한 테슬라 뉴럴 넷의 딥러닝의 구조이다. 그는 이것을 ‘계층적 딥러닝 구조’라 설명하였고 이러한 계층 구조를 통하여 다양한 작업에 ‘구성 요소의 재사용’과 ‘다양한 추론 경로 기능을 공유’할 수 있다고도 하였다. 중추(Backbone), 머리(Head), 말단의 3개 묶음의 8개의 노드(Node)로 구분된 이 구조는 각각 연결되어 있지만 충분히 독립적으로 세분화될 수 있는 모듈식 구성이 특징이다. 또한 모듈식 계층 구조의 장점으로 분산 개발의 가능성까지 이야기하였다.
테슬라가 이번에 소개한 접착제도 필요 없는 독립적 D1 칩과 매우 유사한 구조이다. D1이 모여 트레이닝 타일이 되고, 트레이닝 타일들이 모여 슈퍼컴퓨터(도조)가 되는, 그들의 하드웨어도 필요한 만큼 확장되는 모듈 방식을 취하고 있었다. 딥러닝의 디자인 또한 개별성을 두면서 병렬식으로 구조화하여 결국 다층의 레이어드를 완성하는 식이었다.
테슬라는 소프트웨어의 알고리즘과 하드웨어의 알고리즘을 모두 유사하게 디자인하여 효율을 극대화하고 있다는 생각이다. 예전에 이런 이야기를 들은 적이 있었다. 테슬라 자동차의 전지 효율을 높이기 위해 알고리즘을 바꿔 소프트웨어를 배포하였는데 실제로 효율이 좋아진 것 같다는 것이다. 믿을 수 없겠지만 현실적으로 이것이 가능하다. 아이맥이 실제로 그러하다. 애플에서 개발된 M1 칩으로 생산된 뉴 아이맥은 발열도 없고, 은근히 빠르며 상당히 괜찮은 컴퓨터로 평가받는다. 나 또한 매우 만족하며 사용하고 있다. 놀라울 정도로 빠르다. 애플이 만든 소프트웨어의 알고리즘의 구조에 맞게 하드웨어가 디자인되어 효율을 높였다는 설명이 그때도 있었다.
자동차 업체 중, 전지를 자체적으로 만드는 회사가 적은 상태라 같은 회사 전지를 쓰는 경우도 많을 텐데, 회사마다 각각 전지효율은 이상하리만큼 다르게 표시되고 있다. 사실 2차 전지니, 고체 전지(맞나?)니 하지만, ‘전기’라는 녀석 자체가 저장이 힘든 녀석이라 전지 효율에 큰 발전? 이 있었다고 할 수 없을 정도로 아주 쪼끔씩 좋아지는 식이지, 현격히, 획기적으로 좋아진 부분은 크게 없었다는 생각이다. 만약 전지 효율을 더 이상 높일 수 없다면 선회하여 모터 플랫폼 외에도 다른 전력을 소모하는 자동차 내부 장치와 같은 모든 전력 소비 장치와 운영을 최소 단위부터 효율적으로 빌드업해나가는 것이 현재 전기차 전지 효율을 높이는 노하우가 아닌가 한다.

* 2021, 11 - Tesla, 배터리 스타트업 SiILion 인수
지난 11월 테슬라는 실리온을 인수하였다고 한다. "리튬 이온 에너지 저장 장치 및 배터리에 사용하기에 적합한 높은 중량 비율의 실리콘을 갖는 대면적 양극 및 그 제조 방법”이 그들의 특허 기술로 등록되어 있다고 하는데, 어라~ 새로운 소재라 무척 관심이 가지 않을 수 없다. 제발 좀.
"그건 그렇고 라이다, 레이더 없이 자율주행이 가능하냐고요!" 그것은 알 수 없지만, Karpathy가 얼마나 잘하고 있는지는 확인할 수 있을지도 모르겠다.
'데이터 센트릭' - 2021년, AI계의 새로운 트렌드 - DATA CENTRIC MOVEMENT


Data is food for AI. - Andrew Ng (앤드류 응)
(사진 출처 - scale.com)
구글 브레인의 창립 책임자였고 ‘딥러닝 AI의 설립자’이며 스탠퍼드 대 교수를 겸임하고 있는, '앤드류 응(Andrew Ng)'은 현존하는 AI계의 가장 영향력 있는 인물 중 한 사람이다. 2021년 3월 25일, ‘데이터 센트릭(데이터 중심)’ AI 구축론의 높은 효율성을 제시하는 강연(MLOps)을 시작으로, 현장에서 AI의 실제 개발에 참여하고 있는 엔지니어들의 깊은 공감을 사며, 강한 설득력을 얻고 있는 중이다.
또한 2021년 8월 11일에는 데이터 중심 접근 방식을 향상하는 방법을 구체적으로 알려주는 이벤트도 진행하였다. 그동안 AI의 오류가 발견되면 모델 자체에 문제가 있다고 생각하여 우선적으로 코드 즉 알고리즘을 수정하는 방식에 주목해왔으나, 데이터 중심으로 수정한 결과 훨씬 효과적 결과를 얻음에 따라 코드 중심적 사고에서 데이터 중심적 사고로 접근하는 것의 구체적 방법을 제시한다. 또한 이러한 방법은 시간적, 경제적으로 높은 효율성까지 동반되어 업계의 큰 주목을 함께 받고 있다.
강연은 데이터의 퀄리티에 따라 질 높은 데이터들을 많이 학습하였을지라도 상대적으로 노이즈가 많은 질 낮은 데이터들과 뒤섞이게 되어 오류를 생산한다는 근본적인 원인을 지적하며, 일관적인 ‘데이터 레이블링(Data Labeling)’으로 질 높은 데이터를 명확히 정의하는 것을 선행하여 오류를 최소화하는 과정의 중요성을 이야기하고 있다.
* 이것은 이른바 AI 개발 사이클의 큰 전환점을 시사하고 있다는 생각이다. 유튜브, DeepLearning.AI 채널에서 누구나 볼 수 있다. 최근 Andrew Ng은 애플이 인수한 드라이브에이아이로 영입되었다는 이야기를 어디서 본 듯 하다.


‘머신 러닝(Machine Learning - ML)’에서 주로 사용하는 ‘데이터 레이블링(Data Labeling)’은 AI 개발에 필요한 학습 데이터를 일일이 지정하고 그것이 무엇인지 정확히 입력해주는 작업을 뜻한다. 다시 말해 AI 모델을 구축할 때 AI를 학습시키기 위하여 대량의 원시 데이터를 일일이 지정하고 그것의 주석을 입력해주는 작업이다. 이처럼 작업된 데이터는 AI 운영체제가 데이터를 다룰 때, 추출의 주요 단위로 사용될 요소 중 하나가 되므로 AI 모델 완성의 필수 재료가 된다.
레이블링은 단순한 입력의 작업으로 생각될 수도 있으나, 대부분의 경우, 모델의 콘텍스트를 정확히 이해하여야만 정확한 레이블링이 가능하고 조언하고 있다. 모델 완성을 위한 일관적인 레이블링이 아니라면 AI에게 명확한 패턴 인식이 학습되기 어렵기 때문이다. 또한 일련의 과정을 통해 개별적으로 탄생된 레이블링 샘플들은 동종의 개체는 다시금 ‘세트(SET)’화하여 일군의 단위를 만들어 보다 다양한 동종의 데이터로 인식과 패턴의 명확성을 세트 학습을 통해 높인다. 결과적으로 일관된 레이블링이 아니라면 ‘데이터 세트’ 또한 품질을 보장하기 어렵게 되고 나아가 모델 완성을 어렵게 하는 요소가 될 수밖에 없다.
단순한 ‘머신 러닝(Machine Learning - ML)’은 수학적 알고리즘을 사용하여 패턴을 자동으로 구별하는 것을 목표로 하는데, 이에 AI는 디지털 이미지를 ❶ 획득하고, ❷ 처리하고, ❸ 분석하고, ❹ 이해하여 ❺ 패턴을 인식하게 하여 ❻ 비로소 원하는 데이터를 추출함으로써 기능을 완성하게 될 것이다. 이때, ❶과 ❷작업이 ❸에 도달하도록 AI에게 다양하되 일관된 스펙트럼의 이미지 데이터를 명확히 학습(입력) 해 줘야만 3번의 분석 값 또한 명확해지게 된다. 이에 레이블링 작업, 즉 데이터 작업은 최소 단위부터 매우 중요하다.
모델 중심 VS 데이터 중심
그는 비공식적으로 ArXiv(아카이브 - 과학 논문 저장소)에 발표된 99%의 최신 논문들이 머신러닝 알고리즘에 대한 기술이라는 점을 확인하면서 현재 알고리즘의 과도한 쏠림 현상의 개선점을 시사하였고, 3개월간 76.2%의 완성률을 가지는 AI 모델을 두고, 개선 작업을 진행하자, 모델 중심 코드(알고리즘)에 집중하는 그룹은 전혀 모델 성능 향상이 되지 않은 반면, 데이터 품질 개선으로 접근한 그룹은 무려 16.9%가 개선되어 93.1%의 완성률을 보이고 있음도 함께 소개하여 데이터의 중요성을 다시 한번 이야기하였다.

올해 들어 '캐글(Kaggle)'은 데이터 경연을!

캐글은 기업 등에서 데이터와 해결과제 등을 등록하면 이를 해결하는 모델을 개발하고 경쟁하는 대회 플랫폼이다. AI의 성능 향상을 미션으로 벌이는 유명한 알고리즘 경연 대회인 캐글은 올해는 그동안의 행보와 다르게 알고리즘을 전혀 변경하지 않고 데이터 세트만을 변경하는 식의 Data-centric 대회를 가졌다. 기존의 캐글과는 전혀 다른 방식으로 진행되었다.

캐글 데이터 사이즈 - Andrew Ng은 캐글의 데이터 세트를 조사하는 동안, 데이터 세트의 규모의 대부분이 소규모에서 중규모인 경우가 많았다는 것과 데이터 세트의 크기가 작을 경우, 레이블의 노이즈 문제가 더 많이 강조되는 경향이 있다는 것을 설명하였다.
나쁜 선생님 여러 명과 좋은 선생님 한 명 누가 나을까? (물어볼 걸 물어봐라 좀!)
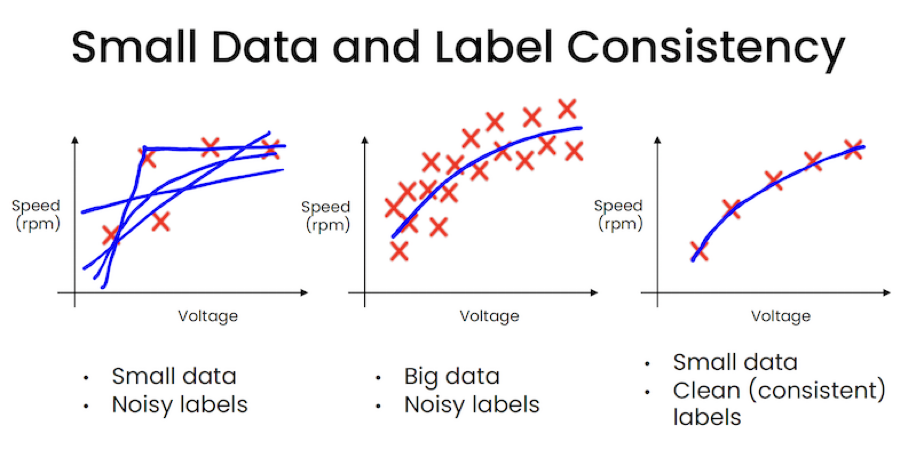
스몰 데이터와 일관된 레이블 - Andrew Ng은 스몰데이터이면서 노이즈가 많은 데이터는 모델의 성능을 떨어뜨리지만, 노이즈가 많더라도 빅데이터일 경우에는 흐름과 방향을 식별할 수 있는 수준이 되어 노이즈가 포함되어 있어도 모델은 적합하다는 것을 설명하였다. 하지만 가장 중요한 것은 스몰데이터일지라도 노이즈가 없는 일관된 레이블의 데이터라면 스몰 데이터로도 충분하다는 것이었다.
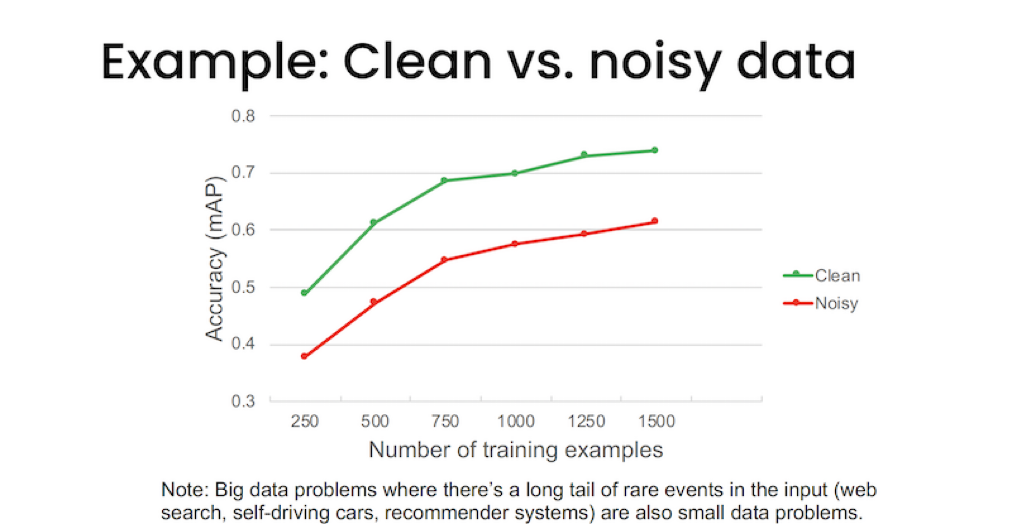
예제: 일관된 데이터와 노이즈가 있는 데이터 - Andrew Ng은 노이즈가 많은 레이블의 경우에는 더 많은 데이터를 수집하거나, 기존의 데이터를 정리할 것을 제안한다. 만약 500개의 데이터가 있고, 그중 노이즈 데이터가 12%를 차지하고 있다고 가정한다면 노이즈 데이터를 정리하거나 500개의 데이터를 더 수집하여야 모델의 효과를 얻을 수 있다고 설명한다. 또한 그래프와 같이 노이즈가 많은 데이터로 구성된 모델의 경우, 성능이 상대적으로 떨어져, 일관된 데이터와 같이 성능을 높이려고 한다면 약 3배에 가까운 데이터 양을 늘려야 한다는 것을 알 수 있다. 따라서 기존의 데이터를 정리하는 것과 더 많은 데이터를 수집하는 것의 비용을 고려하여 여부를 평가해야 한다는 것이다.
* 하지만 자율주행의 경우, 영상 등과 같은 다량의 데이터가 수집되어 빅데이터를 가지고 있을지라도 돌발 상황이나 예외적 상황과 같은 매우 독특한 트래픽이 있는 변수적 상황 등은 상대적으로 데이터가 적기 때문에 문제로 남을 수 있다는 것. (웹 검색, 자율주행, 추천 시스템 등)
그러면 Karpathy의 데이터 세트를 부족하지만 한번 들여다보자~

위 그림은 배포 준비가 끝난 데이터 세트가 얼마를 준비하고 배포되었는지를 보여준다. 내용에 의하면 총 7회의 쉐도우 모드를 거쳐 (고차원의 다양한 시나리오의 8대의 카메라의 초당 36 프레임의 10초로 완성된 비디오) 백만 건을 학습하였고, 60억 개의 정확성 높은 깊이와 속도를 가진 오브젝트 레이블을 학습했다. 이 모든 총량은 1.5페타바이트였다.
컴퓨터 비전 접근으로 테슬라 뉴럴 넷이 깊이와 속도를 이해할 수 있냐는 의심으로 라이다를 채용하는 것인데, 이 문제를 해결하기 위하여 Karpathy는 기계학습을 동원하였다. 테슬라 기계학습 엔지니어들이 만든 정확성 높은 일관된 데이터로 객체 및 관련 속성을 감지하는 학습을 하였다는 것이다. Karpathy는 대규모의 일관된 다양한 데이터 세트가 있고, 이에 대한 대규모 훈련을 할 때, 실제로 성공이 보장된다는 것이다.
기계학습(머신러닝)은 데이터와 기대되는 해답을 입력하면 규칙이 출력되는 형식으로 빠르게 배워 빠르게 결과를 내지만 이 또한 명시적으로 프로그래밍되는 것이 아니라, 데이터를 통해 훈련되는 방식이므로 데이터에 노이즈가 많으면 좋은 결과 값을 가지기 어려울 것이다. 그런데 Karpathy는 지난 몇 개월 동안 내부적으로 이 문제를 두고 작업한 결과는 매우 고무적이었다고(YES!라고 함.) 이야기하였다. 그리고 Karpathy의 데이터는 위의 그림으로도 알 수 있듯이, 일관된, 또 정확한 데이터는 물론 빅데이터를 통해 파이널 데이터 세트를 만들고 있다는 것을 알 수 있다.
자율주행의 최고라 평가받으면서도 왜 대외적 평가는 레벨 2인가~ 여보세요~ 같은 레벨 2가 아니에요! 운전자 참여되면 모두 레벨 2라고요!
도조 프로젝트 - 'DOJO' PROJECT


D1 칩으로 만들어질 슈퍼컴퓨터 '도조(Dojo)'는 뉴럴 넷의 트레이닝(학습)용으로 만들어졌기 때문에 실제 훈련 '도장(道場)'을 뜻한다. 발음 또한 일본의 음독, 그대로 차용, 'DOJO(どうじょう)'로 명명하였다.
* 컴퓨터는 모든 언어가 0과 1일 것이다. 컴퓨팅 덕분으로 다국어 접근이 용이한 지금, 컴퓨터처럼 모색하자면 영어던, 일어던 모두 같은 0과 1이겠다. AI를 개발하는 사람답게 편견 없이 세계어를 사용하는 자세, 왠지 마음에 든다는.

거대한 자본이 없으면 결코 해낼 수 없기에 테슬라 정도가 아니면 쉽게 해내기 어려운 프로젝트인 것만큼은 확실한 것 같다. 최고의 인력과 최고의 리더십, 또 풍부한 자원들이 스텝 바이 스텝으로 목표에 다가가고 있는 모습이다. 테슬라가 개발한 하드웨어는 타사에게도 상용화할 예정이라 한다. 자체 개발을 통해 생산비용은 약 20%가 절감된다는 이야기이다. 성큼 한 발 앞서 가는 테슬라의 진행 방향에 또 하나의 새로운 잠재력이 추가되었다는 생각이다.
한편에서는 우려와 걱정은 물론 반박의 논쟁도 끊이질 않고 있지만 진행 방향과 그 과정은 하나같이 쉬운 길을 택하지 않았으며 어려운 난제에 부딪히더라도 대안을 마련하는 일련의 모습과 리스크를 최소화하는 모습들은 매우 인상 깊었다. 그러나 자율주행은 절대적이 아니지 않은가. 모드(Mode)라는 것을 너무 잊어도 안될 것 같다. 누군가에겐 드라이브 자체가 FUN 할 수 있다는 것이다.
독일차의 섬세함과 견고함, 그리고 정밀함 등은 명성과 가치를 떠나 많은 사람들에게 영감과 의미를 주었다. 지구 상에 항상 레거시로 남아있을 이러한 정서는 하루아침에 사라지는 것이 아니라는 것.
도조 파이팅~! 하드웨어는 잘 모르기도 하지만 이야기가 너무 길어져서 이제 그만~ 저는 현대차와 애플이 잘 되었으면 한돠~

애플은 뭐하나? 타이탄 프로젝트 어떻게 돼가는 건가?? 잡스 오빠가 살아계셨다면 애플 카 나왔.....
'관심 > 관심사' 카테고리의 다른 글
| 정보 엔트로피의 기본 개념 (2) | 2024.12.24 |
|---|---|
| 괜찮은 AI 번역기 '딥엘(DeepL)' (0) | 2023.05.27 |
| 리비안 - Rivian (2) | 2021.11.15 |



댓글